Getting started
| Brief video demonstration of Nextclade Web features. A high resolution version is available here. |
Open clades.nextstrain.org in your browser.
💡 For the best viewing experience we recommend using the latest versions of Firefox or Chrome web browsers on a desktop computer or a large laptop.
⚠️ Using Safari is discouraged due to its poor support of required web technologies.
Nextclade requires 2 kinds of inputs in order to operate:
Sequence data - these are the DNA sequences that will be analyzed. Sometimes, we also call them “query sequences”.
Nextclade reference dataset - this is a set of files which encodes specifics of each pathogen (usually a virus). There is a variety of existing datasets to choose from. Advanced users can create their own datasets, in order to add support for more pathogens.
1. Provide sequencing data
Nextclade Web accepts sequence data in FASTA format.
⚠️ Note that only uncompressed FASTA files are currently supported. FASTQ and compressed files are not. Even a single sequence requires a FASTA header starting with
>.
There are a number of options for providing input data to Nextclade, including:
Drag & Drop a file onto the “upload” area. You can also drag & drop multiple files and directories.
Pick a file from computer storage: click “Select files”. You can also select multiple files and directories.
Provide a URL (link) to a file publicly available on the internet: click the “Link” tab and paste the URL
Paste sequence data from clipboard: click the “Paste” tab and paste the fasta data
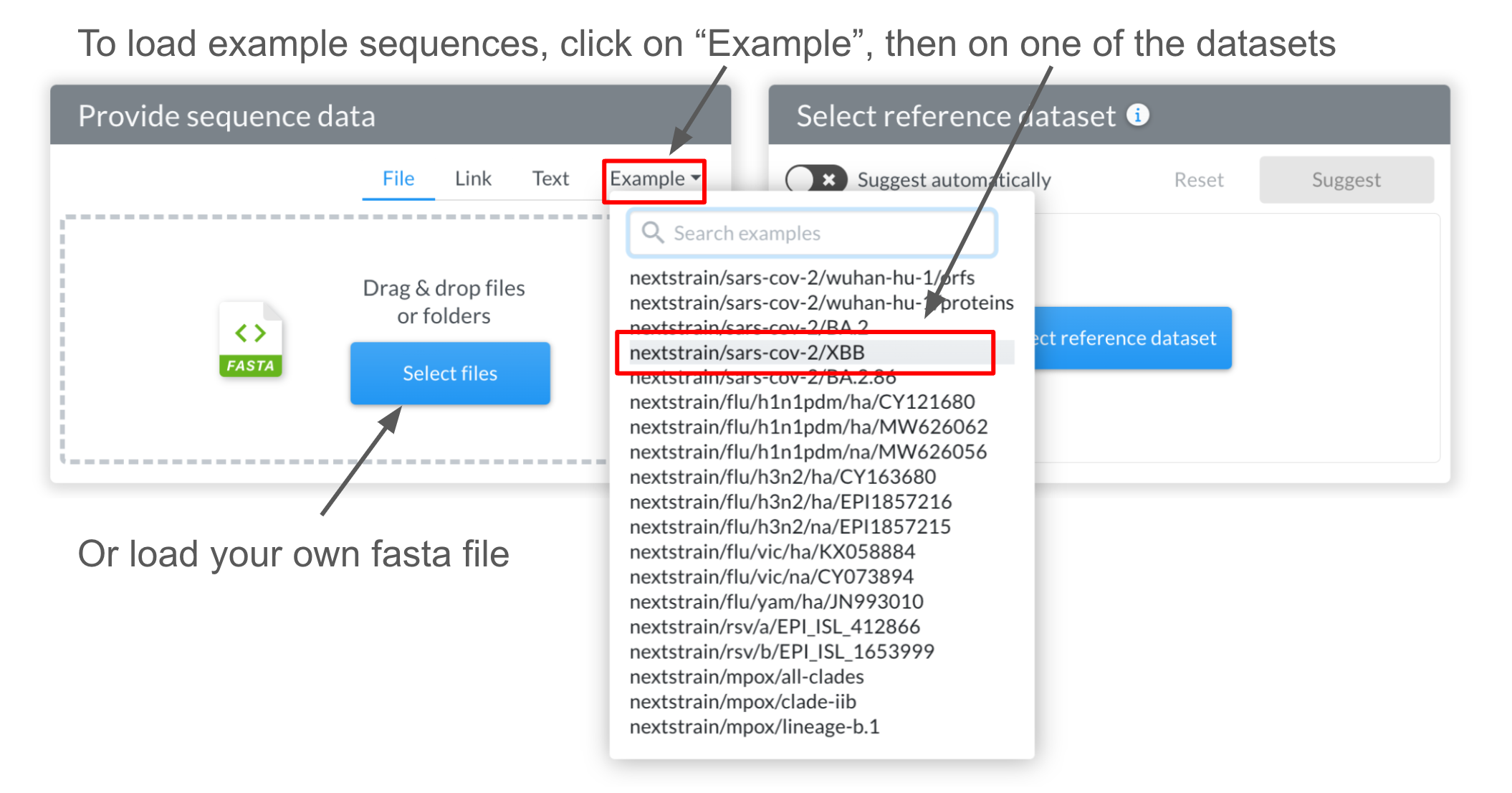
Select example sequences: click “Examples” and choose a pathogen from the menu.
Provide an
input-fastaURL parameter (See URL parameters)
We recommend to analyze at most a few hundred sequences at a time in Nextclade Web. On high-end hardware, Nextclade web can handle up to around 50 MB of input FASTA data. If you need to analyze more sequences, try the command-line version of Nextclade called Nextclade CLI which can handle arbitrarily large datasets (300 GB and more).
In order to allow trying out Nextclade without your own sequences, Nextclade provides example sequences for all supported viruses. You can load example sequences by clicking on “Example” and selecting one of the provided viruses/datasets:
2. Select a dataset
Besides input sequences, Nextclade needs to know which dataset to use to perform the analysis. A dataset is a set of files that configures Nextclade to work with a particular virus or strain. For example, a SARS-CoV-2 dataset contains a SARS-CoV-2 specific reference genome, a genome annotation, a reference tree, and other configuration files. You can learn more about datasets in the Datasets section.
Most users don’t need to worry about the dataset files, because Nextclade provides datasets for a variety of viruses out of the box. The only thing you need to do is to choose an appropriate dataset for your sequences.
If all your sequences can be aligned against a single reference, it’s easiest to use the “Single dataset mode” described directly below. If your sequences are more diverse, for example because they comprise different segments (e.g. influenza) or subtypes (e.g. RSV A and RSV B) you can use Nextclade’s “Multi-dataset mode” to analyze each sequence with an appropriate dataset. How to use this mode is documented further below.
Single dataset mode
Single dataset mode is best when you want to analyze your sequences with a single dataset, i.e. align against the same reference. This mode also allows advanced customisation of dataset files.
Nextclade can automatically suggest compatible datasets by processing the input sequences and comparing them against all available datasets. To do so, click the “Suggest” button after providing some query sequence data (see previous section). If the “Suggest automatically” toggle is turned on (this is the default), adding sequences triggers an automatic suggestion run.
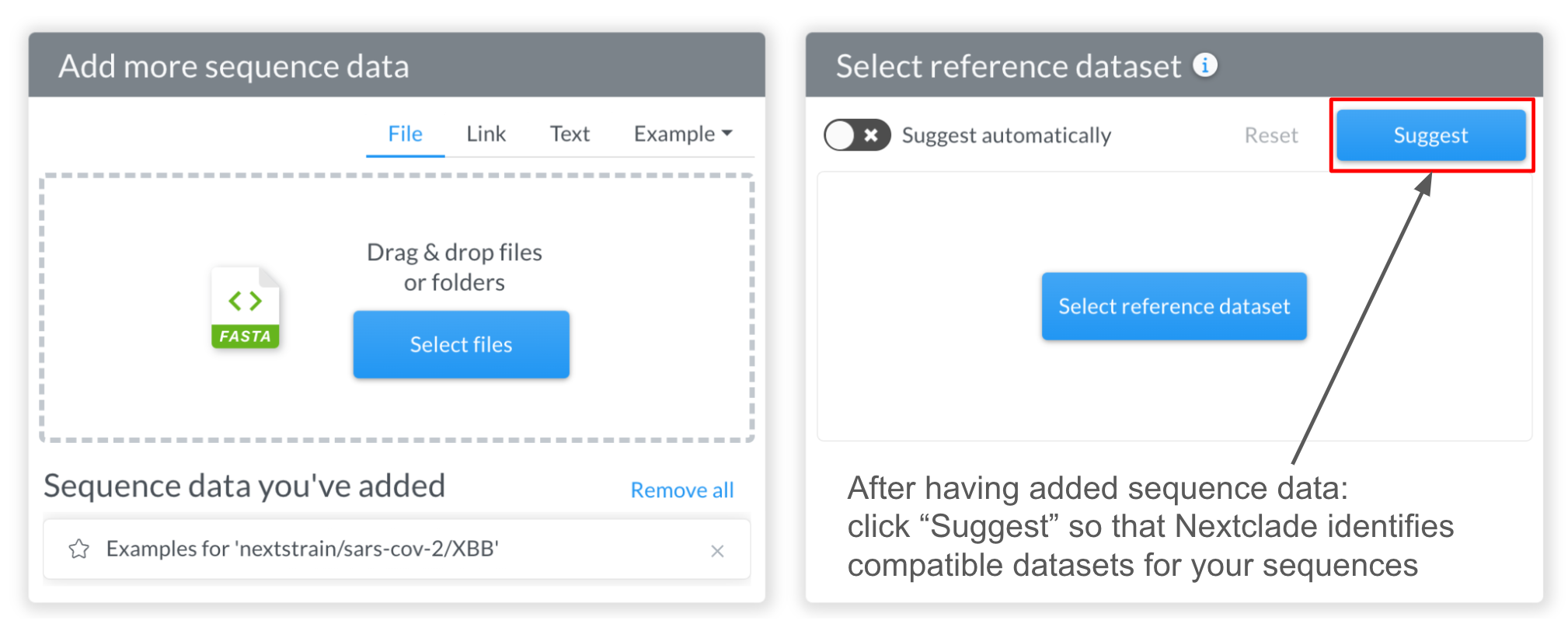
Once the suggestion engine has finished, if no dataset is currently selected, Nextclade will auto-select the best matching dataset: in this case, the SARS-CoV-2 dataset with XBB reference:
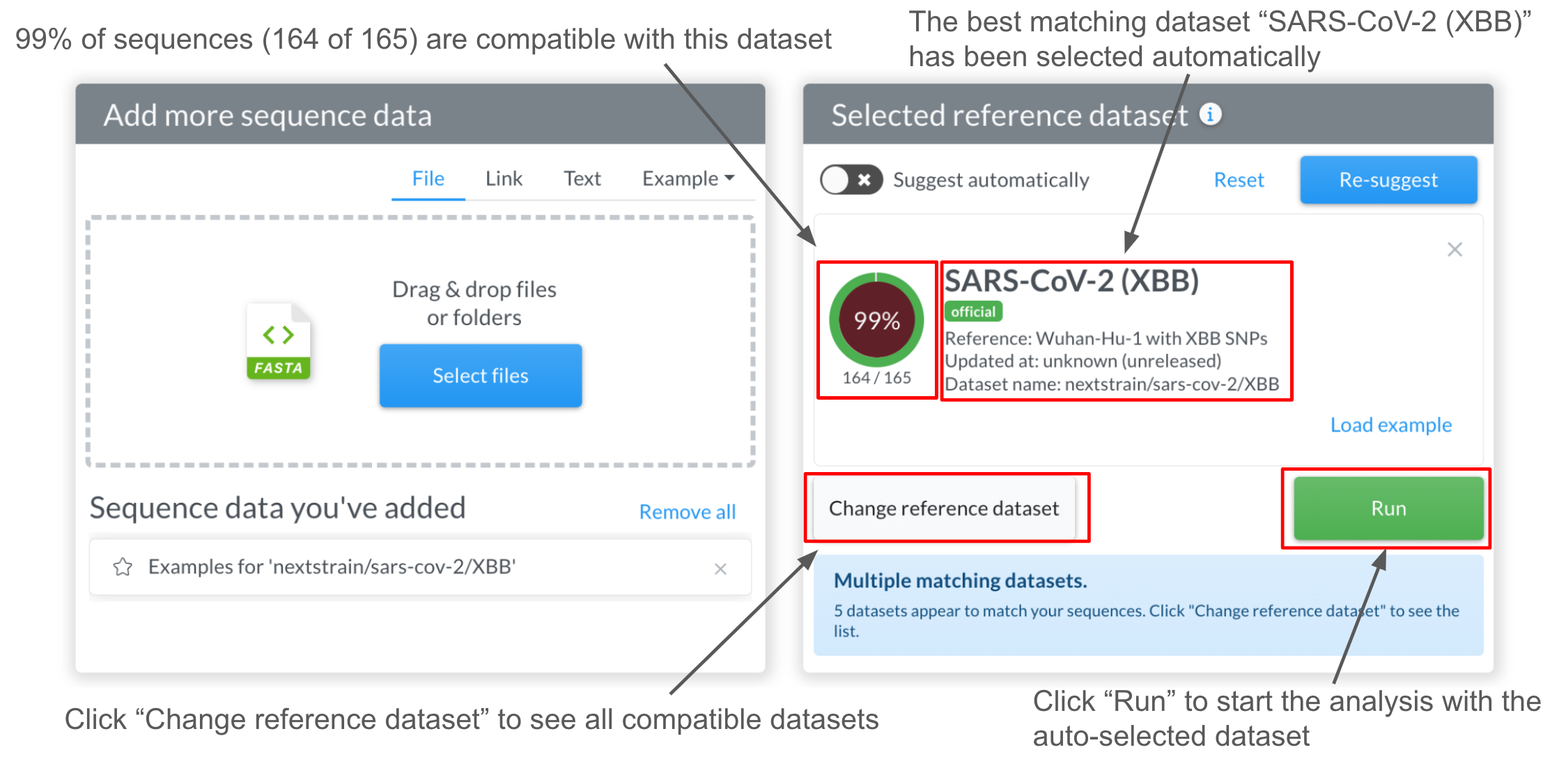
The 99% in the circle mean that, according to our suggestion engine, 99% of the input sequences match the reference sequence of the selected dataset. The message in a blue alert box may show that there are other datasets that are also compatible with the input sequences. To see them, click “Change reference dataset” and it will navigate you to the dataset page.
On the dataset page you can see the list of all existing datasets. The subset of suggested datasets is emphasized, while the rest of the datasets are faded. You can stick to the suggested dataset or select the one you think is more appropriate for your data.
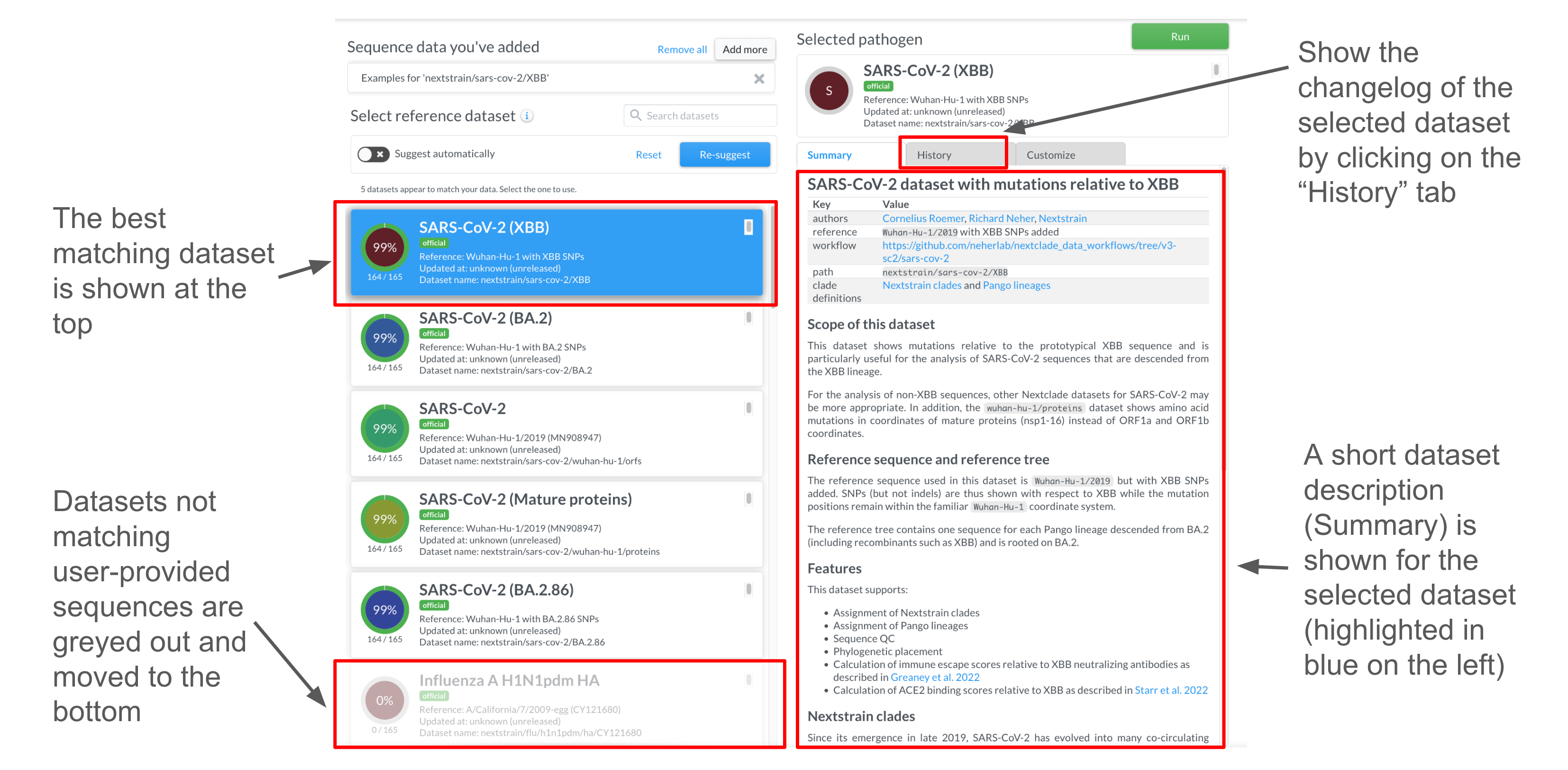
On that page, you can also find some information about dataset in the “Summary” tab, as well as a history of changes in the “History” tab.
Advanced users may override dataset files on the “Customize” tab. This requires good understanding of Input files and of the Nextclade algorithms.
Multi-dataset mode
Introduced in Nextclade version 3.14
With multi-dataset mode, in a single Nextclade run, each of your sequences will be analyzed with an appropriate dataset. This is useful when you want to analyse a diverse set of sequences that require different datasets for different sequences, e.g. RSV A and RSV B. You no longer need to run Nextclade multiple times, once for each dataset.
You can select multi-dataset mode by clicking on the “Multiple datasets” tab in the dataset box on the right of Nextclade’s start screen.
If you click on the “Suggesting” button, Nextclade will analyse each sequence to determine appropriate datasets. When multiple datasets can be used with a given sequence, Nextclade will preferentially choose a dataset that is already selected for another sequence to minimize the number of datasets used, overall.

In multi-dataset mode, Nextclade automatically tries to deduce the most appropriate dataset for each sequence, which results in a list of suggested datasets. When running analysis in multi-dataset mode, you will receive separate results (table, tree and exports) for each dataset.

Currently, the analysis results obtained for different datasets in multi-dataset mode are still entirely separate. After Nextclade has finished running, you can switch between datasets. There is no difference between performing a multi-dataset run and performing multiple runs in single-dataset mode one after another except the convenience of being able to switch and not requiring multiple tabs.
3. Run the analysis
Once you are happy with the set of sequences and with the selected dataset, click “Run” to start the analysis. Nextclade will then automatically navigate to the analysis results page.